Mapping the Code: An Overview of the Deep Live Cam Neural Architecture
Mapping the Code: An Overview of the Deep Live Cam Neural Architecture
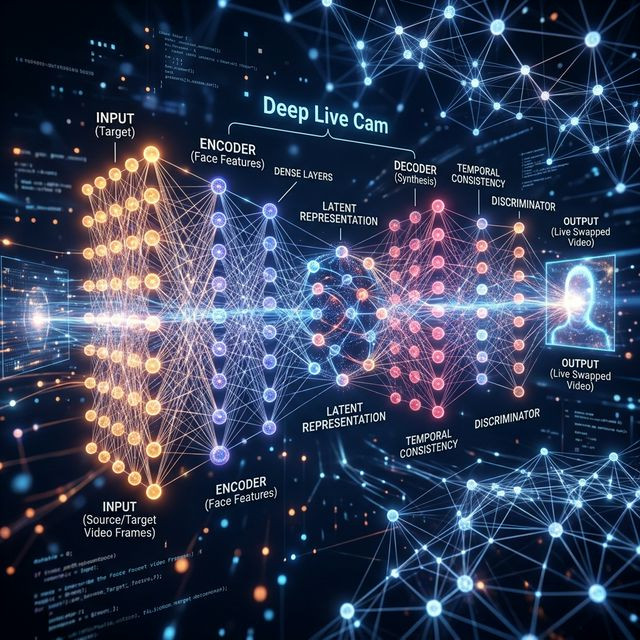
For Python developers gazing at the GitHub repository, the magic of real-time rendering boils down to a brilliantly orchestrated symphony of open-source libraries executing inside a highly compressed graphical interface. Deep Live Cam is not a single monolith, but a masterfully pipelined series of modular neural networks.
The Detection Phase: RetinaFace
Before any face swapping can occur, the computer must locate the bounding box of a human face amidst chaotic background data. This is achieved through ultra-fast bounding-box algorithms, typically RetinaFace or YoloV5-Face. Operating at blistering speeds, this node isolates the facial region and identifies the five key landmarks (two eyes, nose tip, two mouth corners).
The Synthesis Phase: Inswapper
Once the face is cropped and mathematically aligned horizontally, the core ONNX model activates. The pre-trained `inswapper` model encodes the source face (your target image) into a latent 512-dimensional vector. Then, it aggressively decodes this vector, coercing it to conform to the precise facial expressions (pitch, yaw, mouth openness) detected on the webcam feed.
The Final Polish: GFPGAN Enhancement
Because the intermediate synthesis happens at a low resolution (often 128x128 pixels) to ensure speed, the resulting mask is blurry. Here, a Generative Adversarial Network (primarily GFPGAN or CodeFormer) steps in. Operating as a hyper-intelligent upscaler, it mathematically guesses and paints high-definition pores, eyelashes, and skin textures back onto the blurred mask, completing the pipeline and dispensing the final HD frame.

